
A Liquid AI disse que, com seus modelos de fundação, espera alcançar o equilíbrio ideal entre qualidade, latência e memória para tarefas específicas e requisitos de hardware. | Fonte: líquido AI
Nesta semana, a Liquid IA lançou o LFM2, um modelo de fundação líquida (LFM) que a empresa disse que define um novo padrão em qualidade, velocidade e implantação de eficiência de memória.
A mudança de grandes modelos generativos de nuvens distantes para LLMs de inclinação, LLMs, desbloqueia a latência de milissegundos, resiliência off -line e privacidade soberana de dados. Estes são recursos essenciais para telefones, laptops, carros, robôs, wearables, satélites e outros pontos de extremidade que devem raciocinar em tempo real.
A IA líquida projetou o modelo para fornecer uma experiência geral de Gen-AI em todos os dispositivos em todo o setor, desbloqueando um número enorme de dispositivos para cargas de trabalho de IA generativas. Construído em uma nova arquitetura híbrida, o LFM2 oferece duas vezes mais rápido decodificação e preenchimento de desempenho do QWEN3 na CPU. Também supera significativamente os modelos em cada classe de tamanho, tornando -os ideais para alimentar agentes eficientes de IA, informou a empresa.
The Cambridge, Massachusetts empresa disseram esses ganhos de desempenho tornam o LFM2 a escolha ideal para casos de uso local e de borda. Além dos benefícios de implantação, sua nova infraestrutura de arquitetura e treinamento oferece uma melhoria três vezes na eficiência do treinamento em relação à geração LFM anterior.
O co-fundador da IA Liquid e diretora do Laboratório de Ciência da Computação e Ciência da MIT (CSAIL) Daniela Rus entregou uma palestra no Robotics Summit & Expo 2025um evento de desenvolvimento de robótica produzido pelo Relatório Robot.
Os modelos LFM2 estão disponíveis hoje em abraçar o rosto. O Liquid AI está lançando -os sob uma licença aberta, que é baseada no Apache 2.0. A licença permite que os usuários usem livremente modelos LFM2 para fins acadêmicos e de pesquisa. As empresas também podem usar os modelos comercialmente se forem menores (menos de US $ 10 milhões).
A Liquid AI oferece pequenos modelos de fundação multimodal com uma pilha de implantação segura de grau corporativo que transforma todos os dispositivos em um dispositivo AI, localmente. Isso, segundo ele, oferece a oportunidade de obter uma participação estranha no mercado, à medida que as empresas giram da Cloud LLMs para a inteligência econômica, rápida, privada e no local.
https://www.youtube.com/watch?v=vmibynqrs9y
O que o LFM2 pode fazer?
A IA líquida disse LFM2 Consegue treinamento três vezes mais rápido em comparação com sua geração anterior. Também se beneficia de até duas vezes mais rápidas decodificação e velocidade de preenchimento na CPU em comparação com o QWEN3. Além disso, a empresa reivindicou que o LFM2 supera os modelos de tamanho semelhante em várias categorias de referência, incluindo conhecimento, matemática, instruções a seguir e recursos multilíngues.
O LFM2 está equipado com uma nova arquitetura. É um modelo líquido híbrido com portões multiplicativos e pequenos convoluções. Consiste em 16 blocos: 10 blocos de convolução de curto alcance com dupla gama e 6 blocos de atenção da consulta agrupada.
Seja implantado em smartphones, laptops ou veículos, o LFM2 é executado com eficiência em hardware de CPU, GPU e NPU. O sistema de pilha completa da empresa inclui mecanismos de arquitetura, otimização e implantação para acelerar o caminho do protótipo ao produto.
A IA líquida está liberando os pesos de três pontos de verificação densos com parâmetros de 0,35b, 0,7b e 1,2b. Os usuários podem experimentá -los agora no playground líquido, abraçando o rosto e o OpenRouter.
Como o LFM2 se apresenta contra outros modelos?
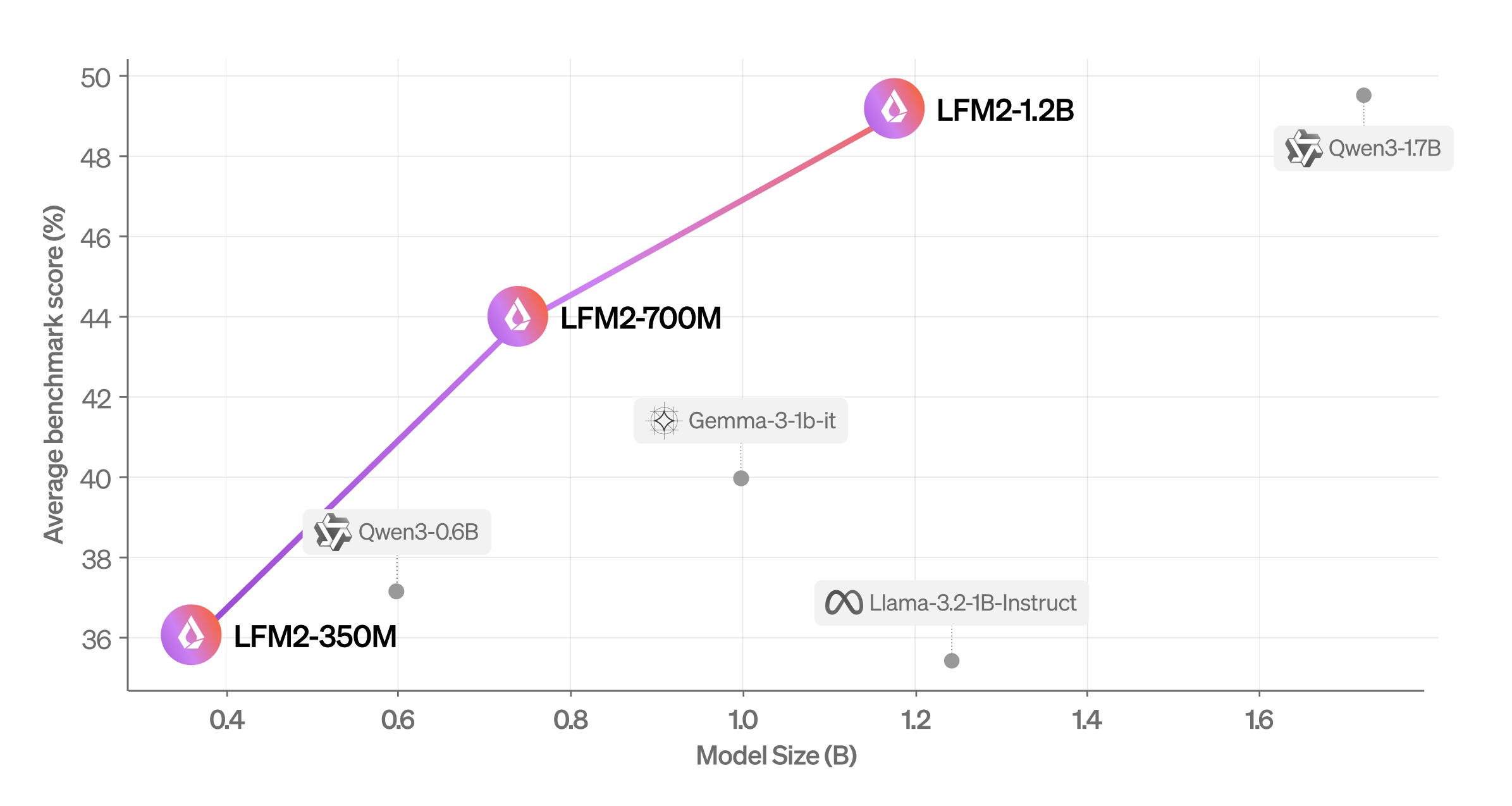
Pontuação média (MMLU, ifeval, ifbench, gsm8k, mmmlu) vs. tamanho do modelo. | Fonte: líquido AI
A Companhia avaliou o LFM2 usando benchmarks automatizados e uma estrutura LLM-AS-A-JUDGE para obter uma visão abrangente de suas capacidades. Ele descobriu que o modelo supera modelos de tamanho semelhante em diferentes categorias de avaliação.
Liquid AI also evaluated LFM2 across seven popular benchmarks covering knowledge (5-shot MMLU, 0-shot GPQA), instruction following (IFEval, IFBench), mathematics (0-shot GSM8K, 5-shot MGSM), and multilingualism (5-shot OpenAI MMMLU, 5-shot MGSM again) with seven languages (Arabic, French, German, Spanish, Japanese, Korean, and Chinês).
Ele descobriu que o LFM2-1.2b tem um desempenho competitivo com o QWEN3-1.7B, um modelo com uma contagem de parâmetros 47% maior. O LFM2-700M supera o Gemma 3 1b It, e seu menor ponto de verificação, LFM2-350M, é competitivo com QWEN3-0.6B e LLAMA 3.2 1B Instruct.
Como a IA líquida treinou LFM2
Para treinar e ampliar o LFM2, a empresa selecionou três tamanhos de modelo (parâmetros de 350m, 700m e 1,2b) direcionando cargas de trabalho de modelo de linguagem de baixa latência no dispositivo. Todos os modelos foram treinados em tokens 10T extraídos de um corpus de pré-treinamento, compreendendo aproximadamente 75% de inglês, 20% multilíngues e 5% de dados de código provenientes da Web e materiais licenciados.
Para as capacidades multilíngues da LFM2, a empresa se concentrou principalmente em idiomas japoneses, árabes, coreanos, espanhóis, franceses e alemães.
Durante o pré-treinamento, a IA líquida alavancou seu LFM1-7B existente como modelo de professor em uma estrutura de destilação de conhecimento. A empresa usou a entropia cruzada entre as saídas do aluno do LFM2 e as saídas do professor LFM1-7B como o sinal de treinamento primário durante todo o processo de treinamento de 10T token. O comprimento do contexto foi estendido durante o pré -treinamento a 32k.
O pós-treinamento começou com um estágio de ajuste fino (SFT) supervisionado em larga escala em uma mistura de dados diversificada para desbloquear as capacidades generalistas. Para esses pequenos modelos, a empresa achou benéfica treinar diretamente em um conjunto representativo de tarefas a jusante, como chamadas de pano ou função. O conjunto de dados é composto por dados sintéticos licenciados, licenciados e direcionados, onde a empresa garante alta qualidade por meio de uma combinação de pontuação quantitativa de amostras e heurísticas qualitativas.
A IA líquida aplica ainda um algoritmo de otimização de preferência direta personalizada com normalização de comprimento em uma combinação de dados offline e dados semi-online. O conjunto de dados semi-online é gerado pela amostragem de várias conclusões a partir de seu modelo, com base em um conjunto de dados SFT de semente.
A empresa então obtém todas as respostas com juízes da LLM e cria pares de preferências, combinando as conclusões mais altas e mais baixas entre as amostras SFT e na política. Os conjuntos de dados offline e semi-online são ainda mais filtrados com base em um limite de pontuação. A IA líquida cria vários pontos de verificação candidatos, variando os hiperparâmetros e as misturas de dados. Finalmente, ele combina uma seleção de seus melhores pontos de verificação em um modelo final por meio de diferentes técnicas de fusão de modelos.