
Dois COBOTS usando lançamentos de avaliação autônoma da FinetUned LBMS para realizar comportamentos de longo horizonte, como a instalação de um rotor de bicicleta. | Fonte: Toyota Research Institute
O Toyota Research Institute (TRI) divulgou esta semana os resultados de seu estudo em grandes modelos de comportamento (LBMS) que podem ser usados para treinar robôs de uso geral. O estudo mostrou que um único LBM pode aprender centenas de tarefas e usar conhecimento prévio para adquirir novas habilidades com 80% menos dados de treinamento.
Os LBMs são pré -treinados em conjuntos de dados de manipulação grandes e diversos. Apesar de sua crescente popularidade, a comunidade de robótica sabe surpreendentemente pouco sobre as nuances do que os LBMs realmente oferecem. O trabalho da TRI visa esclarecer o progresso recente no design de algoritmo e conjunto de dados com este estudo.
Ao todo, a TRI disse que suas descobertas apoiam amplamente o recente aumento na popularidade dos modelos de fundação de robôs no estilo LBM, acrescentando a evidências de que pré-treinamento em larga escala em diversos dados de robôs é um caminho viável para robôs mais capazes, embora com alguns pontos de cautela.
Os robôs de uso geral prometem um futuro em que os robôs domésticos podem fornecer assistência diária. No entanto, não estamos no ponto em que qualquer robô pode enfrentar tarefas domésticas médias. LBMS, ou sistemas de IA incorporados que recebem dados do sensor de robô e ações de saída, podem mudar isso, disse Tri.
Em 2024, a TRI ganhou um prêmio de inovação de robótica RBR50 por seu trabalho construindo LBMS para ensino de robôs rápidos.
Uma visão geral das descobertas de Tri
https://www.youtube.com/watch?v=delpntgzjt4
A TRI treinou uma série de LBMs baseados em difusão em quase 1.700 horas de dados de robôs e conduziu 1.800 lançamentos de avaliação do mundo real e mais de 47.000 lançamentos de simulação para estudar rigorosamente suas capacidades. Descobriu que LBMS:
- Forneça melhorias consistentes de desempenho em relação às políticas de arranhões
- Permitir que novas tarefas sejam aprendidas com 3-5 × menos dados em ambientes desafiadores que exigem robustez a uma variedade de fatores ambientais
- Melhorar constantemente à medida que os dados de pré -treinamento aumentam
Mesmo com apenas algumas centenas de horas diversas de dados e apenas algumas centenas de demos por comportamento, o desempenho saltou de maneira significativa, disse Tri. A pré -treinamento fornece elevação consistente de desempenho em escalas anteriores do que o esperado. Ainda não existe um valor de dados da Internet, mas os benefícios aparecem muito antes dessa escala – um sinal promissor para permitir ciclos virtuosos de aquisição de dados e desempenho inicial, afirmou o TRI.
O conjunto de avaliação da TRI inclui várias tarefas novas e altamente desafiadoras do mundo real do mundo real; FinetUned e avaliado nesse cenário, o LBM pré -treinamento melhora o desempenho, apesar desses comportamentos serem altamente distintos das tarefas pré -treinamento.
Dentro da arquitetura e dados do TRI’s LBMS
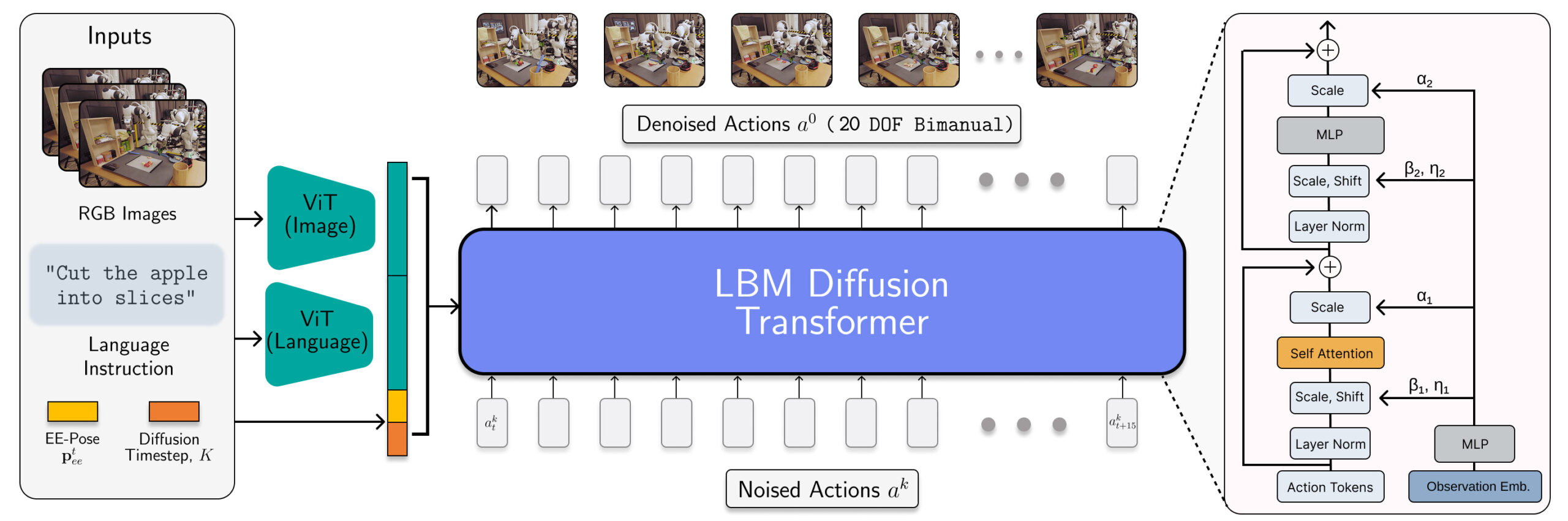
A arquitetura LBM é instanciada como um transformador de difusão que prevê ações do robô. | Fonte: Toyota Research Institute
Os LBMs do TRI são políticas de difusão multitarefa em escala com codificadores de linguagem multimodal de VIT VIV e uma cabeça de denoising transformadora condicionada a observações codificadas via Adaln. Esses modelos consomem câmeras de pulso e cena, propriedade de robôs e instruções de idioma e prevêem 16 textos de ação (1,6 segundos).
Os pesquisadores treinaram os LBMs em uma mistura de 468 horas de dados de teleooperação robô bimanual coletados internamente, 45 horas de dados de teleoperação coletados por simulação, 32 horas de dados de interface de manipulação universal (UMI) e aproximadamente 1.150 horas de dados da Internet curados dos dados do EMBODIDENTE ABRIL.
Embora a proporção de dados de simulação seja pequena, sua inclusão na mistura de pré -treinamento da TRI garante que possa avaliar o mesmo ponto de verificação LBM no SIM e no Real.
Métodos de avaliação do TRI
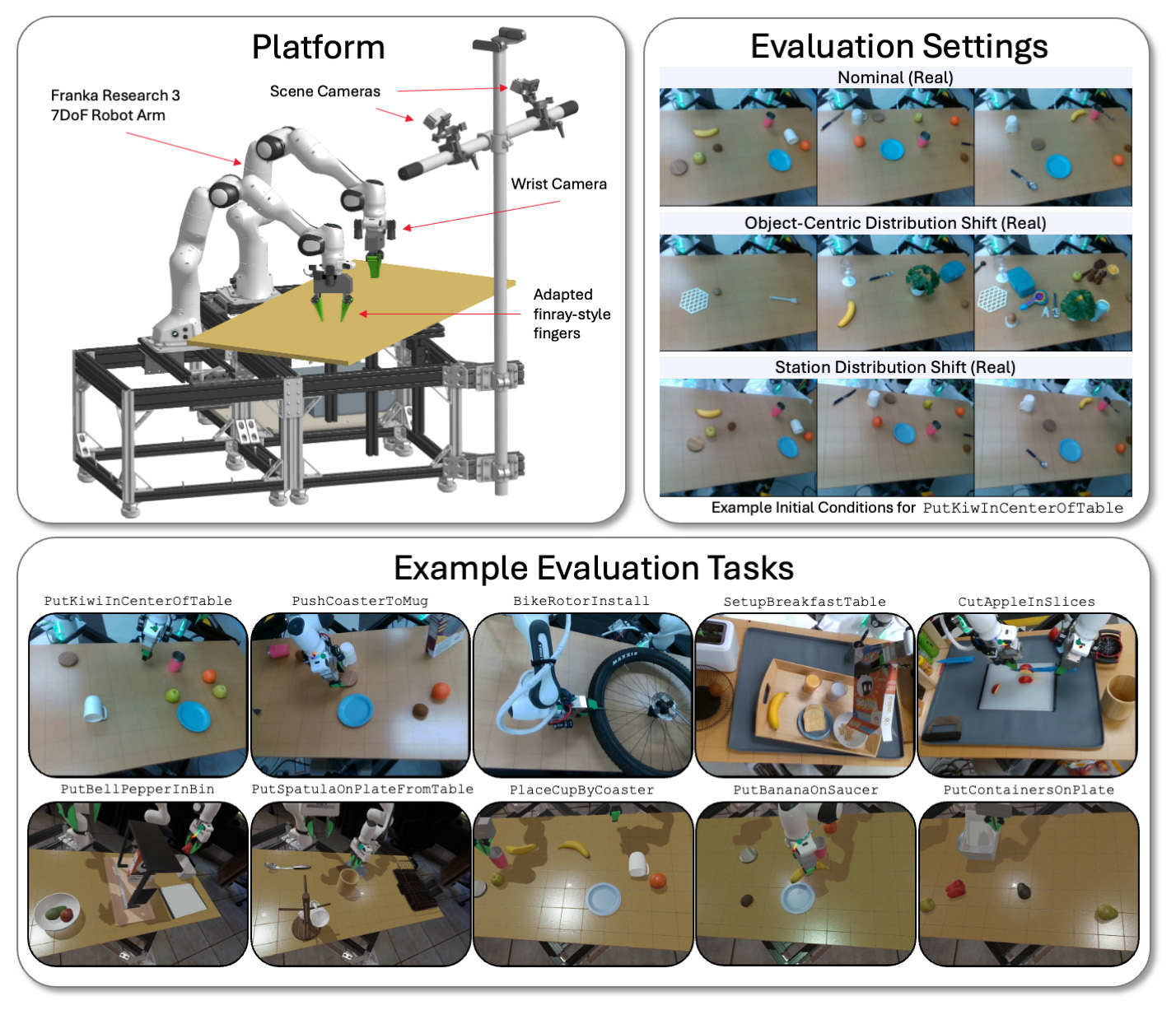
A TRI avalia seus modelos LBM em uma plataforma bimanual em uma variedade de tarefas e condições ambientais na simulação e no mundo real. | Fonte: Toyota Research Institute
A TRI avalia seus LBMs em estações bimanuais físicas e simuladas por Drake, empregando braços de Franka Panda FR3 e até seis câmeras-até duas em cada pulso e duas câmeras de cena estática.
Ele avalia os modelos nas tarefas vistas (presentes nos dados pré-trepingantes) e nas tarefas invisíveis (que o TRI usa para ajustar seu modelo pré-treinado). O conjunto de avaliação do TRI consiste em 16 tarefas de pré-traficante de dores simuladas, 3 tarefas de pré-adulto do mundo real, 5 tarefas simuladas de longo horizonte de longo horizonte e 5 tarefas complexas de longo horizonte de longo horizonte.
Cada modelo foi testado por meio de 50 lançamentos para cada tarefa do mundo real e 200 lançamentos para cada tarefa de simulação. Isso permite um alto nível de rigor estatístico em nossa análise, com os modelos pré -treinados avaliados em 4.200 lançamentos em 29 tarefas.
A TRI disse que controla cuidadosamente as condições iniciais para serem consistentes no mundo real e na simulação. Ele também realiza testes cegos no estilo A/B no mundo real com significância estatística calculada por meio de uma estrutura de teste de hipóteses seqüenciais.
Muitos dos efeitos que os pesquisadores observados foram mensuráveis apenas com tamanhos de amostra maior do que o padrão e testes estatísticos cuidadosos que não são padronizados para a robótica empírica. É fácil para ruído devido à variação experimental para diminuir os efeitos que estão sendo medidos, e muitos documentos de robótica podem estar medindo ruído estatístico devido ao poder estatístico insuficiente.
As principais tocas da Tri da pesquisa
Um dos principais da equipe Takeaways é que o desempenho da FinetUned melhora suavemente com o aumento dos dados de pré -treinamento. Nas escalas de dados que examinamos, a TRI não viu evidências de descontinuidades de desempenho ou pontos de inflexão nítidos; O escala de IA aparece vivo e bem na robótica.
A TRI sofreu resultados mistos com LBMs pré-ridicularizados não-finais, no entanto. Encorajantemente, descobriu que uma única rede é capaz de aprender muitas tarefas simultaneamente, mas não observa um desempenho superior consistente do treinamento de tarefas únicas de zero, sem ajuste fino. A TRI espera que isso seja parcialmente devido à direção da linguagem de seu modelo.
Nos testes internos, a TRI disse que viu alguns sinais iniciais promissores de que protótipos maiores do VLA superam parte dessa dificuldade, mas é necessário mais trabalho para examinar rigorosamente esse efeito em modelos de capacidade de língua superior.
Quando se trata de pontos de cautela, a TRI disse que opções sutis de design, como a normalização dos dados, podem ter grandes efeitos no desempenho, geralmente dominando as alterações arquitetônicas ou algorítmicas. É importante que essas opções de design sejam cuidadosamente isoladas para evitar confundir a fonte de alterações de desempenho.